发布日期:2026-04-30 12:18 点击次数:159
科学数据正在以惊人的速度堆积,但大量有价值的数字依然被埋在论文文本里,等待人工去发现。
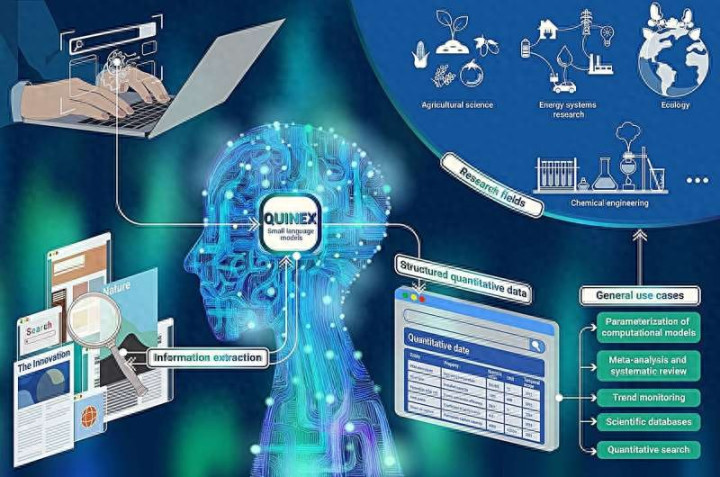
德国于利希研究中心的研究团队开发了一套名为Quinex的AI框架,专门用于自动识别科学论文中的定量数据,将散落在文字叙述中的数字、单位、测量条件等信息,整理成结构化的可用数据集。相关成果已发表在《创新》杂志上。
这件事听起来像是文字处理工具的升级版,但它解决的问题远比看起来更紧迫。
数据就在那里,但没人能全部读完
在能源、气候、材料科学等研究领域,每一篇论文里都密布着数字:效率百分比、温度范围、生产成本、碳排放量。这些数据对于建立模型、识别趋势、制定政策具有直接价值。
问题是,这些数字并不存在于整齐的表格里,它们藏在句子的中间,夹在方法描述和背景说明之间,需要人读懂上下文才能判断它的含义。
更棘手的是,相关论文的数量正在以指数级增长。以能源转型领域为例,每年新发表的研究论文已经远超任何团队手工处理的上限。想要系统性地汇总某项技术在过去十年的效率演变,靠人工阅读提取几乎是不可能完成的任务。
Quinex想要解决的,正是这个卡口。
Quinex是“定量信息提取”的缩写,其核心是经过专门训练的语言模型,能够识别科学文本中的数值,将数值与对应单位匹配,并判断这个数字描述的是什么、在什么条件下测得、来自哪里、时间节点是何时。
举一个具体例子:论文中出现“2025年假设效率水平为63%至71%”这样的句子,Quinex会将其解析为包含年份、效率范围、测量方法和文献来源的结构化数据条目,而不是仅仅提取“63%”和“71%”两个孤立的数字。
这种对上下文的理解能力,是Quinex区别于简单数字提取工具的关键所在。
在准确率方面,Quinex在数字及相关单位识别上的F1准确率约为98%,在定量属性分类和实体分类上分别达到87%和82%。这些数据来自专门构建的训练数据集和方法论改进,在同类系统中处于领先水平。
轻量、开放,让更多研究者用得上
值得关注的是,Quinex并非依赖庞大的专有大模型,而是基于相对小型、高效的开放语言模型构建。
这个选择有其明确的逻辑。大型封闭模型计算成本高昂,部署门槛高,对于资源有限的研究机构并不友好。于利希团队的目标是开发一个“强大、透明且资源高效”的工具,让AI辅助的科学数据分析真正具备可及性。
在实际测试中,研究团队将Quinex应用于来自多个领域的数千篇科学摘要,系统成功提取了各类能源技术的电力生产成本、人体最大摄氧量、地震震级与位置数据,以及光伏材料的能隙数值,提取结果与参考数据高度吻合。
负责该项目的Jann Weinand博士表示,Quinex使AI在科学数据分析中更易获得,而这正是团队从一开始就设定的目标。
于利希研究中心已将Quinex作为开源项目对外发布,全球研究人员可以免费测试、扩展和调整这套系统,使其适应各自领域的需求,从能源研究到化学、生物医学均可覆盖。
当然,Quinex并非无懈可击。团队坦承,当关键引用信息分散在文本各处时,系统有时会出现误解。领衔作者Jan Göpfert明确表示,数字和单位的识别非常可靠,因为它们直接来自原文,不存在“幻觉”问题,但对上下文的判断仍有出错的可能。
正因如此,团队将Quinex定位为辅助工具而非替代品,每一个被识别的数字都可以追溯到原始来源,必要时在原文中直接标注,解读结果的责任仍由研究者承担。
接下来,团队计划通过引入更多领域专属的训练数据集和模型,进一步提升系统在细分领域的适应性和精度。
科研的洪流在加速,能帮助研究者在数据海洋里更快找到方向的工具,正在变得越来越不可或缺。
Powered by 爱游戏怎么进入游戏界面 @2013-2022 RSS地图 HTML地图
Copyright Powered by365站群 © 2013-2024